
海狮是一款垂直搜索专用网页正文抽取系统,它应用了领先的结构化抽取技术,采用XSLT模板抽取文档网址,采用DOM抽取其正文内容,成功率98%以上。 海狮功能非常强大,能从搜索引擎结果列表中获得文档网址并抽取,也能对整个网站进行正文抽取,非常适合于网络文章采集工作,并能进行文档查找和管理,适用于垂直搜索、SP服务等领域。
一、提供WEB管理接口,操作方便
海狮启动后,用户可用浏览器访问http://localhost:6476(注:6476为默认端口,用户也可修改此端口号),登录后 便可进行查看系统信息、正文抽取、文档管理和修改登录用户名及密码的工作。正文抽取包括新建、修改、复制、启动、停止等 项,用于控制抽取任务。一切都是通过浏览器来进行,非常简单。
二、抽取任务运行时间多样,选择灵活
为了适应各种情况,海狮提供了多种运行时间选择:手动运行,每天X时X分,每周周XX时X分,每月X日X点X分,每年X月X日X时X分。这些时间选择,完全满足了正文抽取任务的要求。
每项任务都可选择自己的运行时间,任务启动后,海狮会在合适的时刻运行此项任务,执行正文的抽取工作。
三、支持多种数据库
海狮支持通用的数据库PostgreSQL,MySQL,Oracle,SQL Server,支持嵌入式数据库HSQLDB。HSQLDB已内置到海狮中, 勿需另外安装,方便用户测试和执行轻量级的抓取任务。如果抓取任务多,并发运行的线程多,就需要采用PostgreSQL数据库。注意,数据库均需采用utf8编码,这样才能保证输入汉字不会出现乱码现象。
四、正文内容直接入库并索引
海狮能将抽取到的正文内容直接存到数据库中,并建立索引。系统提供文档管理接口,方便用户查询和管理收集到的文档。
五、系统能自动收集URL种子
在海狮运行抓取任务过程中,URL种子是由系统自动采集的,勿需用户参与,并且用户可以设置过滤规则,过滤掉不需要的种子。 另外,为了适应某些网页的URL链接不用<a href="xxx">来书写,导致系统采集不到的问题,海狮提供了模板接口(seed), 能采集到这些隐藏的种子,从而抓取到相应的数据。
六、采用XSLT模板结构化抽取
海狮使用结构化的抽取手段,模板需用XSLT语言书写,用户可充分利用语言的特性来抽取数据,格式化数据。模板中用docseed来标注文档URL种子。 海狮获取网页数据后,利用此模板得到文档URL,下载、抽取、保存、索引,自动运行,用户勿需任何操作。
七、能在自动登录后进行采集工作
对于那些需要登录才能进行采集的网站,海狮提供了自动登录的支持,支持基本认证、表单认证和自定义认证,功能强大。自定义认证扩展性最强, 它把认证实现交给用户,用户实现IFormLogin接口,把jar包放到userprovided下,就能使用了。
海狮,让正文抽取更简单!让文章采集更方便!
sealion-2.2-installer.exe
(适用于Windows系统)
sealion-2.2-fc9.tar.gz
(适用于Fedora Core 9兼容的Linux系统)
sealion-2.2-el5.tar.gz
(适用于RedHat EL 5/CentOS兼容的Linux系统)
*安装海狮*
WINDOWS: 双击海狮安装程序,最后启动海狮服务。
LINUX: 解压海狮安装包,执行bin/sealion start,启动海狮服务。
海狮启动后,通过浏览器访问海狮所在端口(如http://localhost:6476)即可进入到安装画面。在安装 画面1中选择界面语言后执行下一步。在安装画面2中,输入管理员的用户名及密码,数据库连接设置 (包括数据库类型,所在主机,所在端口,数据库用户,该用户的密码),点击“确定”结束安装。
*登录海狮*
海狮安装成功后,通过浏览器访问海狮所在端口(如http://localhost:6476),使用安装时设置的用户名和 密码即可登录进海狮控制台。
*海狮控制台*
在海狮控制台中,可以查看系统信息,正文抽取,文档管理,修改登录密码及退出系统。
一、系统信息
系统信息显示当前海狮的版本、注册信息以及当前JAVA运行环境相关数据。如果未注册,用户需要提供MAC地址,该地址会显示在注册信息中。获得注册码后,点击“现在注册”, 输入注册码,完成注册。注册以后,需要重启一下海狮。
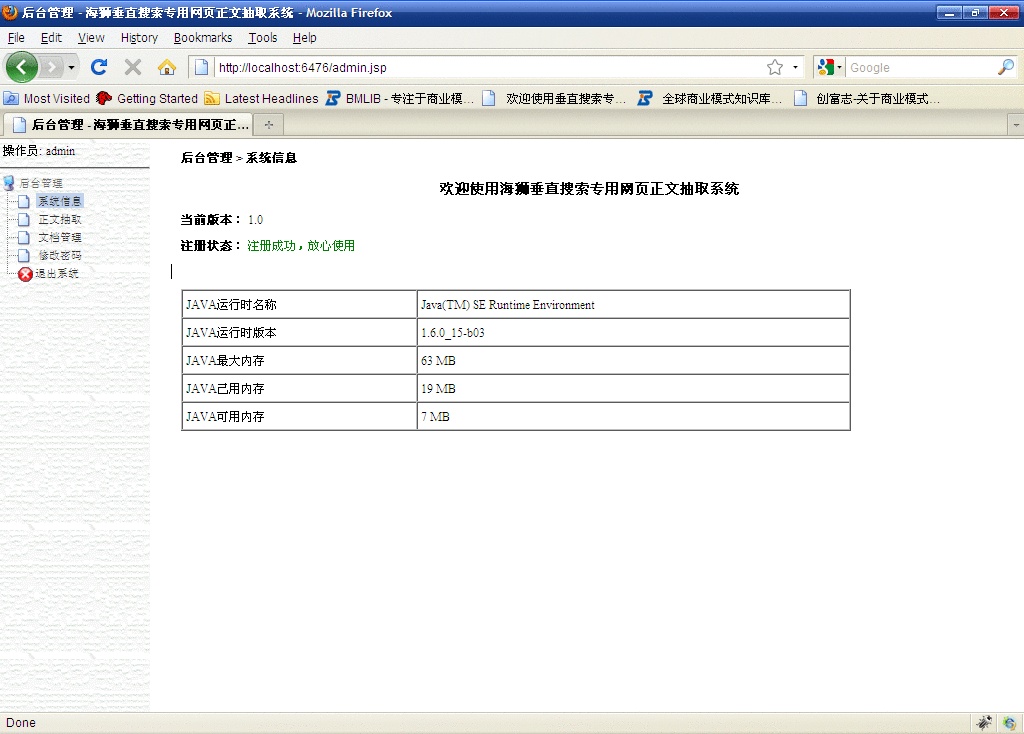 |
| 海狮控制台 - 系统信息 |
二、正文抽取
2.1 搜索结果抽取
对于需要从谷歌、百度等搜索结果得到目标文章网址的任务,使用此抽取类型。
海狮将正文抽取工作定义为任务,每项任务可以在设定的时间以多线程方式运行,最大线程数受限于任务 本身的设置。每个线程相当于传统意义的网络蜘蛛或爬虫。可执行的操作如下:
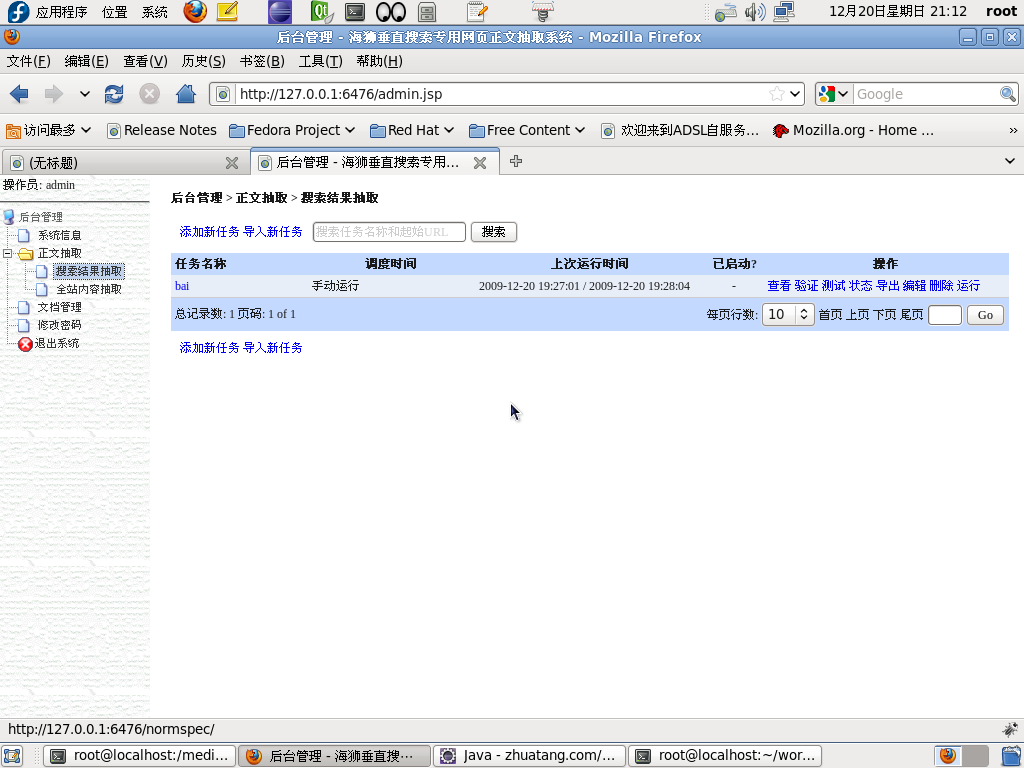 |
| 海狮控制台 - 搜索结果正文抽取 |
1) 添加新任务
点击“添加新任务”即可进入新任务画面。需要输入如下内容
必须唯一,不能重复。
说明从哪个网址开始抓取。
有两类URL过滤规则,一是拒绝规则,另一个是接受规则。规则可以是匹配文本(只在文字在URL中出现即可),也可以匹配正则表达式。
默认为不需要登录。海狮还支持“通过基本认证登录”、“通过表单认证登录”和“自定义认证登录”。
抓取的最大深度。默认为不限制。
也即并发抓取的最多爬虫数。
在抓取前,最好让海狮等一段时间,减少服务器的压力。
一般使用系统默认的爬虫设置即可。若有特殊需要,选择“用户自定义”,修改一下设置。
用于抽取正文所在网页或下一级URL种子的XSLT模板。在此模板中,使用docseed节点保存文档网址,另外,可使用seed节点保存隐藏的下一级URL种子。注,一般的URL种子系统会自行收集,用户勿需操作。
输入用于测试模板工作是否正常的网址
选定任务执行的时间,可手动也可自动。
点击“确定”完成任务添加。
2) 查看
显示任务的具体内容供查看。
3) 验证
验证登录是否成功。
4) 测试
测试模板执行情况。若抽取不到任何数据,有可能是模板写得有问题。
5) 状态
显示当前正在抓取的网址。
6) 导出
导出任务为XML文件,此文件能在“导入新任务”中导入。
7) 编辑
编辑任务,内容同“添加新任务”。
8) 删除
删除任务。
9) 运行
任务为手动运行时,点击“运行”就能马上执行这项任务。
10) 启动
任务为自动执行的任务时,点击“启动”后,此项任务将进入启动状态,时机一到就会执行。
11) 停止
在任务启动或正在运行时,点击“停止”可中止任务的执行。
12) 暂停
在任务正在运行时,点击“暂停”可暂停任务运行。
13) 继续
在任务处在暂停时,点击“继续”可让此任务继续运行。
14) 导入新任务
2.2 全站内容抽取
如果需要对某个网站的文章进行抽取,使用此抽取类型。
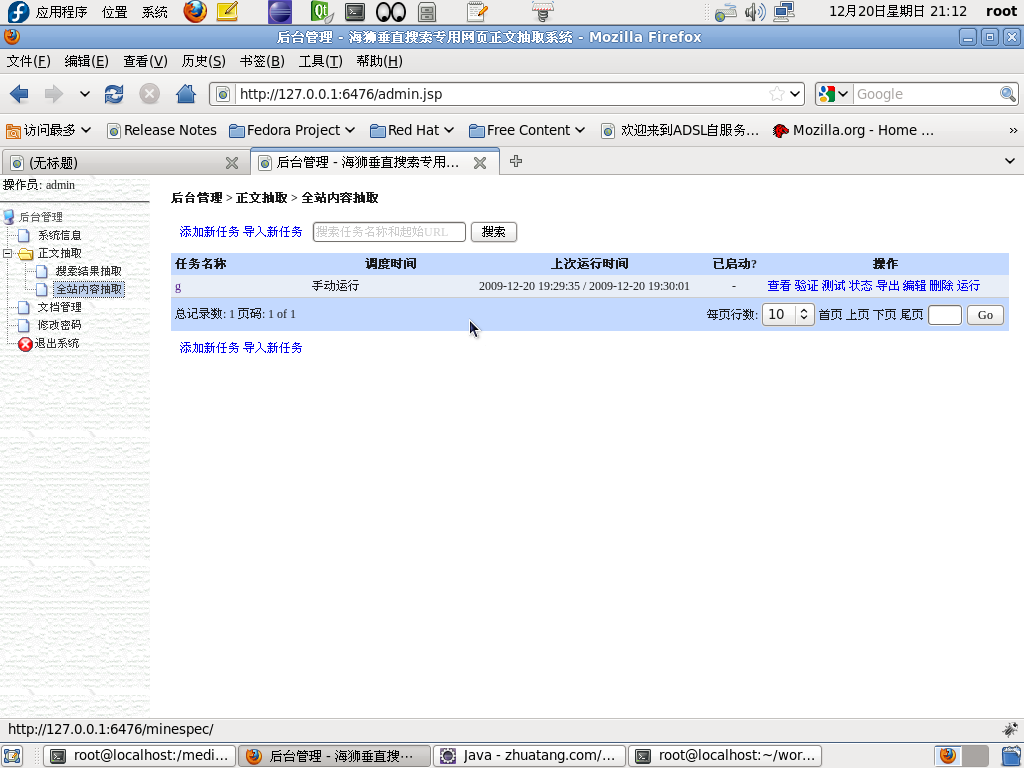 |
| 海狮控制台 - 全站内容正文抽取 |
全站内容抽取任务与搜索结果抽取类似,不同的是它不需要输入数据抽取模板,简便不少。其中的正文包含关键字是可选项,当有内容时,抓到的文章必须包含其中关键字之一。
三、文档管理
在文档管理中,用户能看到海狮采集到的所有文档,可以查看正文快照、正文内容和网页快照,也可删除文档。 用户还可以搜索文档,从标题和内容中搜索,并可限定是某个任务采集的文档,也能限定是哪一天采集的。
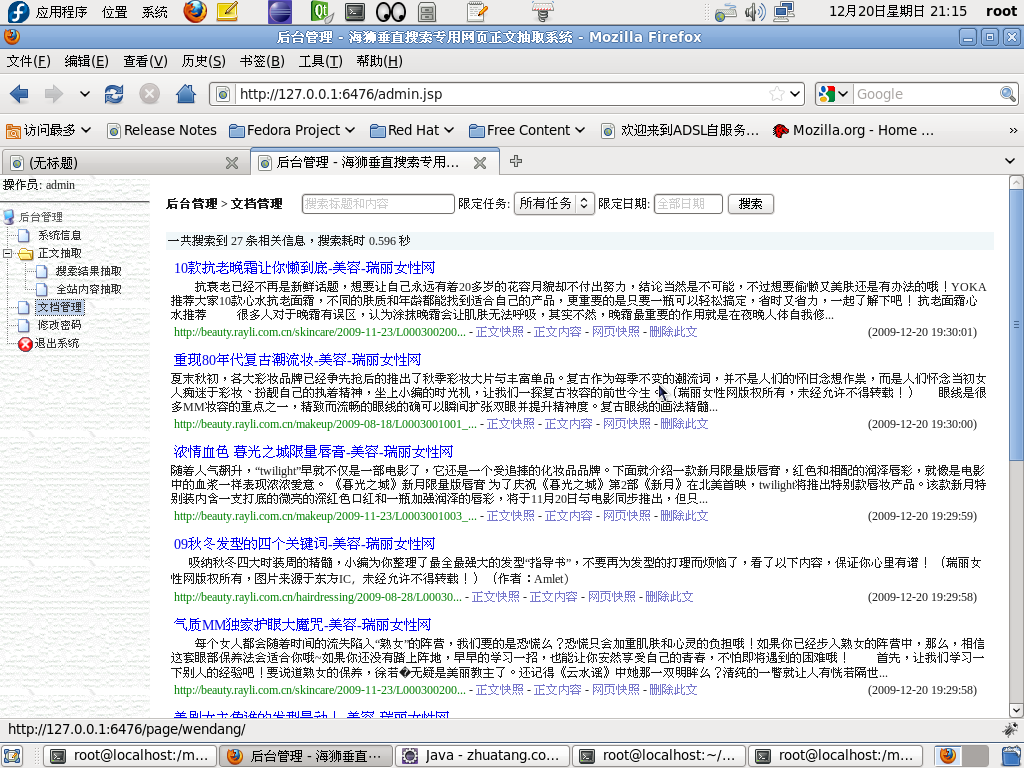 |
| 海狮控制台 - 文档管理 |
四、修改密码
在此界面下可修改登录海狮控制台的用户名及密码。
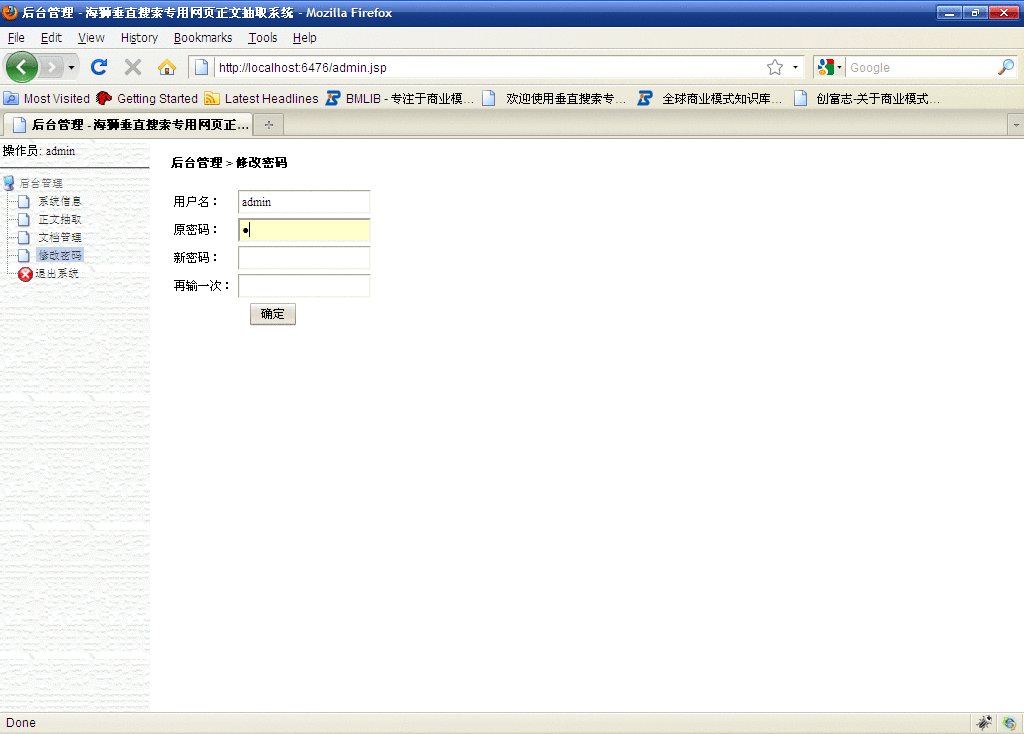 |
| 海狮控制台 - 修改密码 |
五、退出系统
起始URL: http://www.google.cn/search?hl=zh-CN&source=hp&q=%E5%B9%BC%E5%84%BF+%E5%A4%8F%E5%AD%A3%E9%A5%AE%E9%A3%9F&btnG=Google+%E6%90%9C%E7%B4%A2&aq=f&oq= URL过滤规则: 接受符合如下规则的URL: 匹配文本 http://www.google.cn/search?hl=zh-CN 网站登录: 不需要登录 最大深度: 无限制 最大线程数: 2 等待时间: 100 毫秒 爬虫设置: 使用系统默认值 数据抽取模板: <xsl:for-each select="//li[@class='g']/h3/a/@href"> <docseed> <url><xsl:value-of select="."/></url> </docseed> </xsl:for-each> 模板验证网址: http://www.google.cn/search?hl=zh-CN&num=100&newwindow=1&q=%E5%B9%BC%E5%84%BF+%E5%A4%8F%E5%AD%A3%E9%A5%AE%E9%A3%9F&start=100&sa=N
起始URL: http://www.baidu.com/s?wd=%D3%D7%B6%F9+%CF%C4%BC%BE%D2%FB%CA%B3 URL过滤规则: 接受符合如下规则的URL: 匹配文本 http://www.baidu.com/s?wd=%D3%D7%B6%F9%20%CF%C4%BC%BE%D2%FB%CA%B3 网站登录: 不需要登录 最大深度: 1 最大线程数: 2 等待时间: 100 毫秒 爬虫设置: 使用系统默认值 数据抽取模板: <xsl:for-each select="//td[@class='f']/a/@href"> <docseed> <url><xsl:value-of select="."/></url> </docseed> </xsl:for-each> 模板验证网址: http://www.baidu.com/s?wd=%D3%D7%B6%F9+%CF%C4%BC%BE%D2%FB%CA%B3